Stable Video Diffusion — Convert Text and Images to Videos, by Shrinivasan Sankar
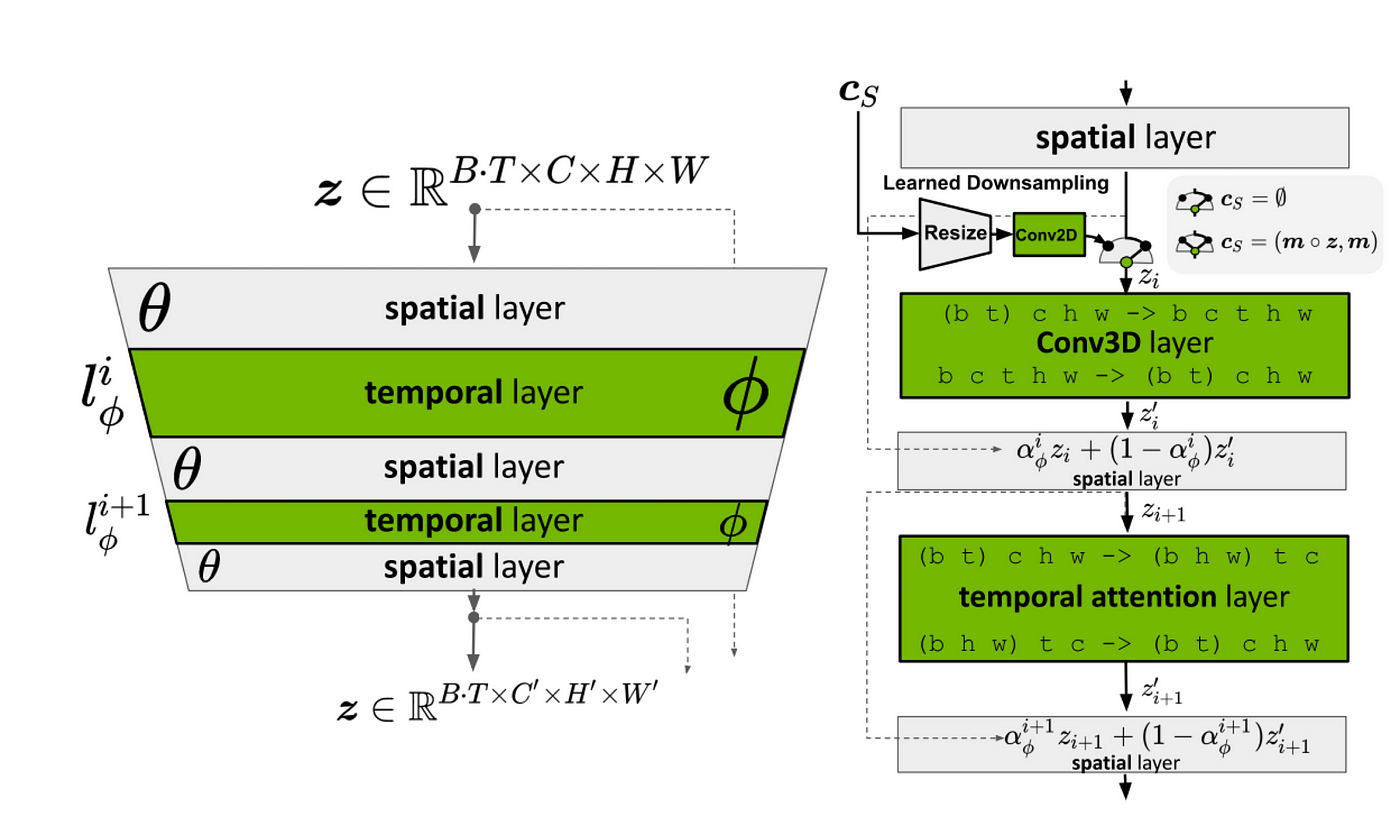
Diving deeper into the Stable Video Diffusion model, its architecture, the proposed Large Video Dataset, and the results Stability AI, one of the leading players in the image generation space, has…

Alpha and Dimensions: Two Wild Settings of Training LoRA in Stable Diffusion, by Ashe Junius

Stable Video Diffusion — Convert Text and Images to Videos, by Shrinivasan Sankar

Generating Videos from Images with Stable Video Diffusion and FiftyOne, by Daniel Gural, Voxel51

Lumiere — The most promising Text-to-Video model yet from Google, by Shrinivasan Sankar, Feb, 2024
Model Quantization in Deep Neural Networks

Ira KEMELMACHER, Assistant Professor, PhD, University of Washington Seattle, Seattle, UW, Department of Computer Science and Engineering

Stable Video Diffusion — Convert Text and Images to Videos, by Shrinivasan Sankar

NeurIPS 2023

PDF) PODIA-3D: Domain Adaptation of 3D Generative Model Across Large Domain Gap Using Pose-Preserved Text-to-Image Diffusion

Chapter 2 cmc, diffusion & theories
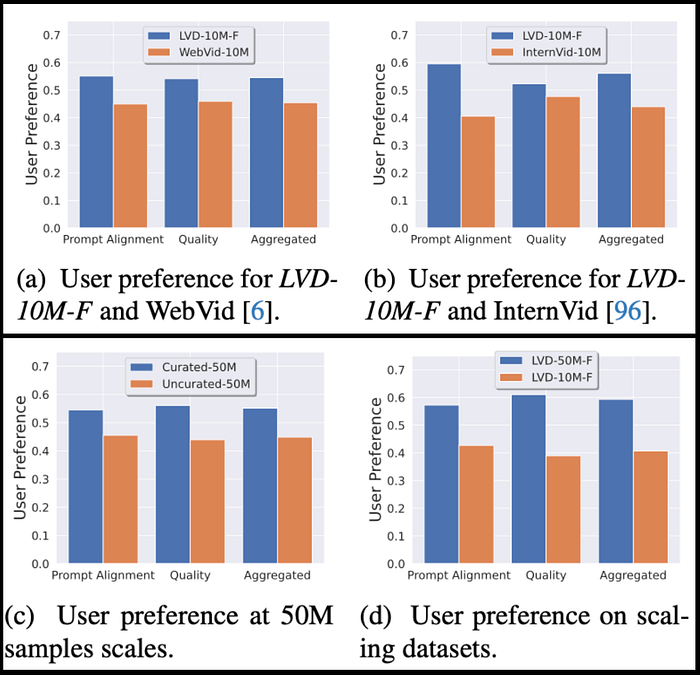
Stable Video Diffusion — Convert Text and Images to Videos

Amity Science, Technology & Innovation Foundation (ASTIF)
GitHub - zhtjtcz/Mine-Arxiv

Stable Video Diffusion: The Three-Stage Training Process for Cutting-Edge Video Generation

Sensors December-1 2023 - Browse Articles